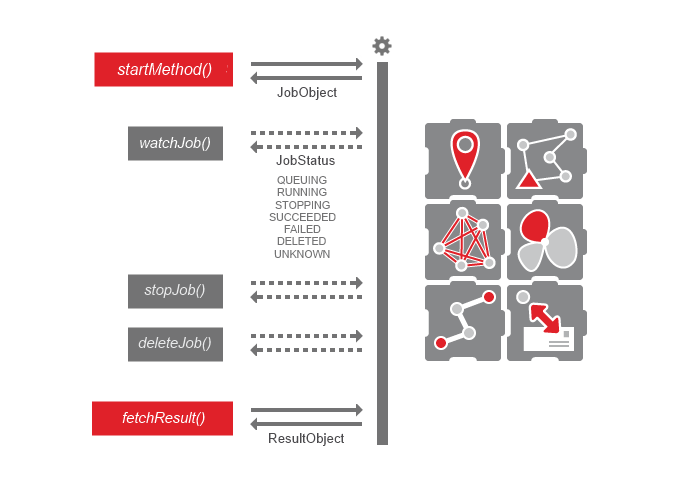
As of PTV xServer 1.18 there is now an alternative protocol for potentially long running requests. Instead of single HTTP requests that stay idle until a response is being sent, the initial request will start a background job running on the server. Clients have to query the job status to see when it has finished, then ask for the result. The server will store the result until it has been fetched.
A job is the representation of an asynchronous transaction. It has a status which may include further detailed progress information. When finished, a job also has a result which may be an error message.
Jobs are kept persistent on the server for a certain period.
These are the benefits of using asynchronous protocol.
In order to use job requests, the PTV xServer has to persist responses until they are fetched. This is done with the help of a JDBC database and works out of the box for a single PTV xServer.
For a cluster of PTV xServer you need a central database. If you need a highly available solution you have to set up replication to your backup systems as well.
You can replace the bundled database with your own.
Please refer to the Administator's Guide for general database information.
For job management nearly any JDBC database can be used. It is requisite that the BLOB API is fully implemented by the JDBC interface, which is not the case for PostgreSQL database management system.
The schema of the necessary database table XSERVER_JOBS is defined as follows:
CREATE TABLE "JOB"."XSERVER_JOBS"( ID varchar(36) PRIMARY KEY NOT NULL, XSERVER varchar(18), METHOD varchar(50), STATUS varchar(20) NOT NULL, ELAPSED bigint, PROGRESS blob, RESULT blob, FINISHTIME bigint, FETCHTIME bigint, LASTUPDATETIME bigint, USERID varchar(36) ); CREATE INDEX XSERVER_JOBS_IDX1 ON "JOB"."XSERVER_JOBS"(STATUS); CREATE INDEX XSERVER_JOBS_IDX2 ON "JOB"."XSERVER_JOBS"(FINISHTIME); CREATE INDEX XSERVER_JOBS_IDX3 ON "JOB"."XSERVER_JOBS"(FETCHTIME); CREATE INDEX XSERVER_JOBS_IDX4 ON "JOB"."XSERVER_JOBS"(LASTUPDATETIME);
In order to set up a cluster of PTV xServer, one central database has to be set up and defined in the PTV xServer configuration files, ideally but not necessarily on a separate dedicated server.
You can designate one of the local databases as the central database, as long as you configure the load balancer properly - your database server will have less CPU power left for requests.
The configuration can be found in job-management-db.xml. Standard configuration of the Apache Derby database for PTV xRoute Server looks like the following
conf/job-management-db.xml
<bean id="hikariConfigJob" class="com.zaxxer.hikari.HikariConfig">
<property name="poolName" value="springHikariCPJob" />
<property name="connectionTestQuery" value="VALUES 1" />
<property name="connectionTimeout" value="5000" />
<property name="dataSourceClassName" value="org.apache.derby.jdbc.ClientDataSource" />
<property name="maximumPoolSize" value="10" />
<property name="dataSourceProperties">
<props>
<prop key="serverName">localhost</prop>
<prop key="databaseName">job</prop>
<prop key="user">JOB</prop>
<prop key="password">JOB</prop>
<prop key="portNumber">50036</prop>
</props>
</property>
</bean>
Please refer to your database vendor's manual to find out more about automatic replication.
Jobs have to be cleaned up periodically. Each PTV xServer comes with an automatic cleanup mechanism which will remove fetched, unfetched, and zombie jobs.
The job life cycle status (finished, fetched, zombie) is separate from its logical status (waiting, running, succeeded etc.) and only available from the database table, querying FINISHTIME, FETCHTIME and LASTUPDATETIME.
FINISHTIME but zero FETCHTIME.FINISHTIME and FETCHTIME.FINISHTIME and the LASTUPDATETIME is too far in the past.The retention periods for each type of job can be configured in xserver.properties:
jobResultRetentionTime - time to live for unfetched jobs. This should be a generous amount of time (days or weeks) and is meant as a protection against jobs forgotten by the client.fetchedJobResultRetentionTime - time to live for fetched jobs. This period should not be too long (minutes or hours) to protect the database against excessive growth but still allow a grace period during which clients can retry a download in case of network issues.zombieJobRetentionTime - time to live for unfinished and no longer updated jobs. This period should be short (hours) and is meant to clean up "zombie" (or "orphaned") jobs in case of crashes of the processing instance.You can effectively deactivate the automatic cleanup task by setting these properties to a very high value, in case you want to provide your own cleanup mechanism.
The asynchronous protocol no longer consists of a single HTTP message with a request and response pair that form a transaction but a sequence of such HTTP message exchanges. It is important to understand these messages as well as the underlaying Job object and its statuses.
Every long running transaction of the form
runLong(RequestParameters): ResultType
is replaceable with a pair of operations:
startRunLong(RequestParameters): Job
fetchResultType(jobId: string): ResultType
All start operations begin with the prefix start, and closing operations begin with fetch.
In addition, the protocol requires the use of the generic operations
watchJob(jobId: String, watchOptions: WatchOptions): Job
Documentation watchJob
stopJob(jobId: String): Job
Documentation stopJob
deleteJob(jobId: String): Job
Documentation deleteJob
The Job object models meta information about the server job. It contains the following attributes:
id: string - the globally unique id of the job, used to retrieve the job meta data and the results
status: JobStatus - the status of the job
elapsedTime: int - the uptime of the job, useful to interpret the novelty of a job status
progress: JobProgress - the progress information for the job; this is an optional attribute and may be missing. If a progress is available, its concrete type depends on the operation; for instance, bulk operations always return a BulkJobProgress. See the PTV xServer use-case documentation for details. If the request is finished, the progress values represent the state when the request was finished.
All job-related operations except fetch will return a Job object. The status of the job will be QUEUING when returned from the start operation, STOPPING when returned from the stopJob operation, and DELETED when returned from the deleteJob operation. The watchJob operation can return any of the possible status codes:
| job status | description | watchable | has progress? | can fetch? | can stop? | can delete? |
|---|---|---|---|---|---|---|
QUEUING
|
the job has been scheduled for execution | when server is under load and the job has to wait | no | no | no | yes |
RUNNING
|
the job is being executed | if the result is not yet available | yes | no | yes | yes |
STOPPING
|
the job is being finished prematurely | until the current processing step has finished | yes | no | yes (ignored) | yes |
SUCCEEDED
|
the job was successful | after processing has terminated | yes | yes | yes (ignored) | yes (erases) |
FAILED
|
the job has failed | after processing has terminated | yes | yes (returns with the exception) | yes (ignored) | yes (erases) |
DELETED
|
the job has been deleted | while the job has not yet been terminated and cleaned up | no | no | no | yes (ignored) |
UNKNOWN
|
no current job with this id | if id is wrong, or job has already been deleted or fetched | no | no | no | yes (ignored) |
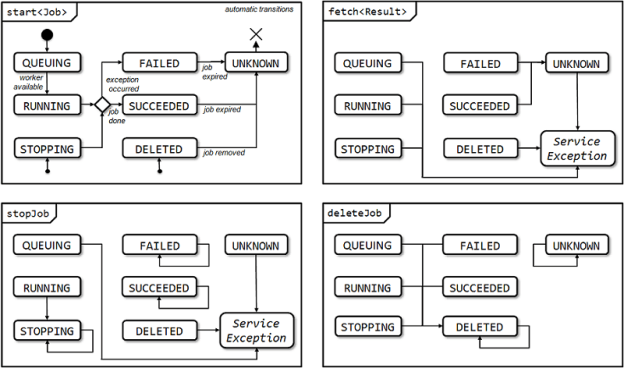
The following diagram illustrates all possible status changes.
Operation watchJob
The watchJob operation will return immediately if the job has state SUCCEEDED, FAILED, DELETED or UNKNOWN. Otherwise, the operation will wait for a status update. If no update happens before a set timeout (maximumPollingPeriod), watchJob will report the last status and only the run time of the job has changed.
WatchJob can return for progress updates while in state RUNNING. This is useful to inform end users about the progress. To enable this behaviour, specify the millisecond period for the progress updates. WatchJob will wait at least this period for a more up to date progress and report only the latest. If no new progress update arrives during the specified period, watchJob will wait for and return with the next available progress update. This mechanism helps to control server and client overhead by coalescing very frequent progress updates. If no progress waiting period is defined, progress will only be sent as part of status updates.
fetchThe fetch operation is only admissible for job status SUCCEEDED or FAILED. In case of FAILED, fetch will report the service exception of the job as result object.
After a fetch of the result object following status SUCCEEDED or FAILED, this object will be erased after a short retention period from the server. This period can be configured within the xserver.properties (default: 5 minutes). If a result object is available but never fetched, it will also expire from the server after a default retention period of 1 week. This period may also be changed within xserver.properties .
stopJobRUNNING jobs can be requested to terminate as soon as possible so that preliminary results can be retrieved using the appropriate fetch method. This can be useful when while watching the job progress the user decides that something does not work at all (for instance, all results of a bulk requests so far were failures), or that the results already suffice (for instance, the current state of a long running optimization is good enough).
stopJob will fail if the job is not RUNNING. For convenience reasons, it is admissible to stop an already STOPPING or a finished job. In these cases, the operation has no effect.
deleteJobThe delete operation will attempt to delete a job with the given id. Once the delete has been requested, there is no way to cancel the delete and get the results of the job.
If the job has not yet started, the request will be removed from the server queue. If the job is already finished, deleteJob will erase the results as well; this can be used to clean up results from the server without having to fetch them.
The DELETED state may not be visible for the client if it works quickly; in that case, watchJob will report an UNKNOWN job. For convenience reasons, it is admissible to send a delete to an already DELETED or an UNKNOWN job. In these cases, the operation has no effect.
A typical transaction is done like this, as pseudocode:
myjobid = startRunLong(request).id do jobstatus = watchJob(myjobid).status while jobstatus not in [ FAILED, SUCCEEDED, DELETED, UNKNOWN ] if jobstatus in [ FAILED, SUCCEEDED ] then myresult = fetchResponseType(myjobid) end
Of course, this transaction is the most simple form. You usually want to do more:
handle error conditions,
automatic retries in case of temporary connectivity issues,
display progress for users (in interactive scenarios),
allow users to stop/delete jobs (in interactive scenarios).
The clients bundled with PTV xServer provide convenience functions for such transactions.
Copyright © 2025 PTV Logistics GmbH All rights reserved. | Imprint